Reclink Data System
Overview
Reclink maintains a data system which is designed to provide for the data needs of a number of groups of users:
- Staff managing programs;
- Management overseeing operations;
- Staff undertaking reporting to the board, funders and stakeholders;
- Staff tendering for funding;
- Evaluators evaluating existing or past programs;
- Researchers collaborating with Reclink to understand the impact of programs
Understanding Reclink’s Data Architecture
This document explains in simple terms how our data system works - from collecting information to creating useful reports and dashboards.
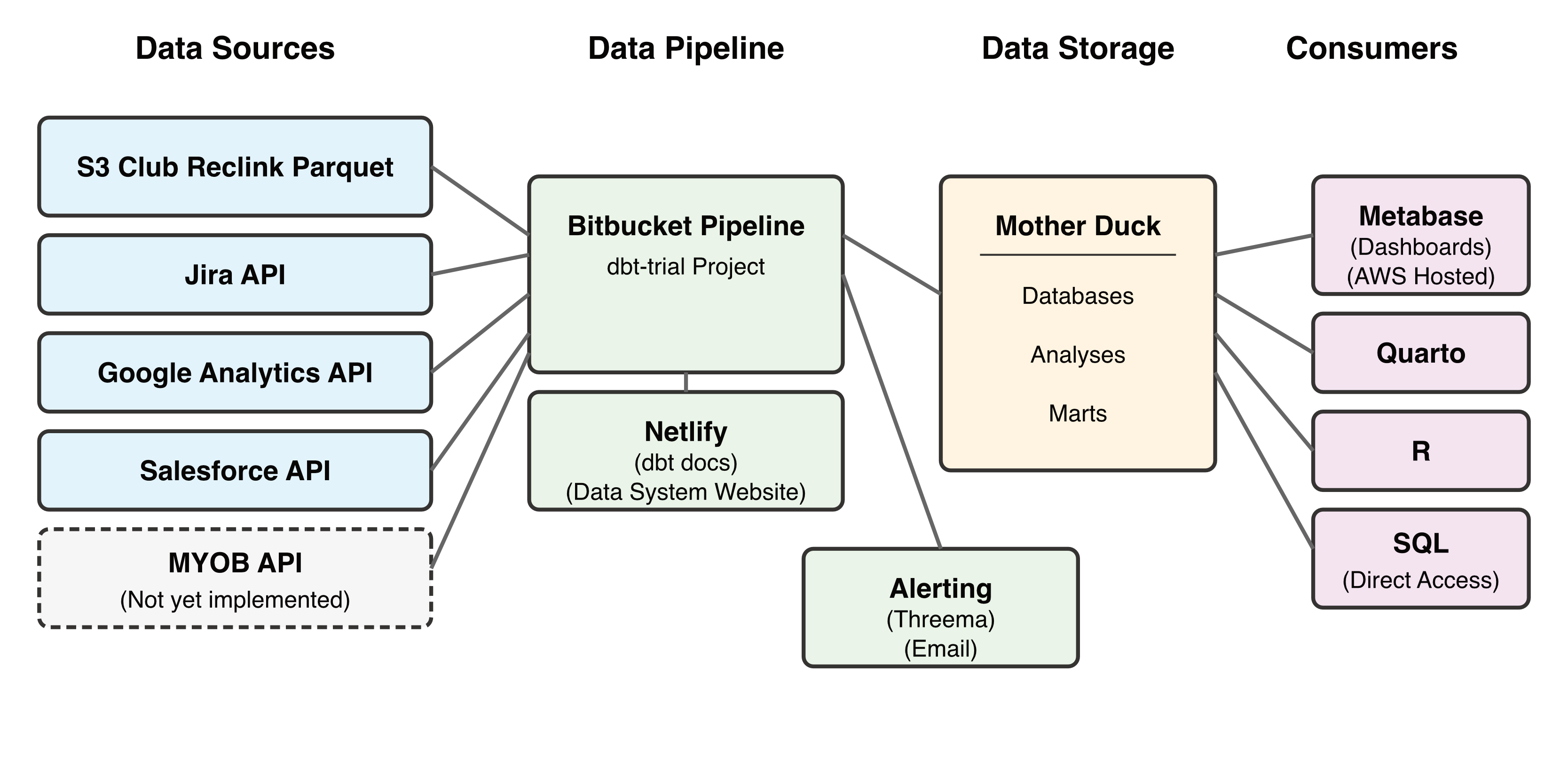
The Data Journey: From Source to Insights
Data in our organisation flows through a series of steps, as shown in the diagram. Here’s what each component does:
Data Sources
APIs (Application Programming Interfaces) are like digital messengers that allow different software systems to talk to each other. They provide a standardised way for us to collect data from various services:
Jira API: Fetches project management data about tasks, bugs, and work progress
Google Analytics API: Collects website visitor information and behaviour
Salesforce API: Gathers customer relationship management data
MYOB API: Will provide financial and accounting data (not yet implemented)
S3 Club Reclink Parquet Files are specially formatted data files that contain information from Club Reclink.
Data Processing
Bitbucket Pipeline is our automated “data assembly line”. It:
Runs on a schedule to collect fresh data from files and APIs
Processes and transforms raw data into usable formats
Uses dbt (data build tool) to model our data
Performs quality checks and testing
Loads the results into our database
dbt (data build tool) is a key technology in our pipeline that:
Transforms raw data into reliable, analytics-ready datasets
Applies business logic consistently across all data models
Enables version control of our data transformations
Creates documentation of data lineage (how data flows through our system)
Ensures data quality through automated testing
Netlify hosts two important web resources:
dbt docs: Technical documentation about our data models, automatically generated by dbt
Data System Website: User-friendly guides and documentation built with Quarto that explain how to use our data system, including tutorials, best practices, and examples
Data Storage
Mother Duck is our cloud database system built on DuckDB technology. DuckDB is a modern analytical database designed to be fast and easy to use. Within our Mother Duck database, we have:
Databases: The underlying storage of all our information and contain
Analyses: Pre-built analytical queries that answer specific questions
Marts: Organised, business-ready datasets focused on specific areas
Alerting
Our system includes automated Alerting that can notify the team when:
Data processing encounters problems
Data quality issues are detected
Scheduled updates complete successfully
Alerts are sent via:
Threema: A secure messaging app for immediate notifications
Email: For less urgent notifications and detailed reports
Data Consumers
Once data is processed and stored, several tools can access and use it:
Metabase: Creates interactive dashboards and visualisations that anyone can use without technical knowledge
Quarto: Produces publication-quality reports combining text, code, and visualisations. It’s also used to build our Data System Website with comprehensive documentation
R: A statistical programming language used for advanced data analysis
SQL: A query language that allows direct database access for custom data exploration
How It All Works Together
Data flows in from sources (APIs and files)
The Bitbucket Pipeline collects this raw data
dbt transforms the raw data into well-structured, business-ready datasets
The processed data is stored in Mother Duck’s databases as analyses, and marts
dbt generates documentation that helps users understand the data
Alerting systems monitor the process and notify the team of any issues
Users access insights through dashboards (Metabase), reports (Quarto), analysis (R), or direct queries (SQL)
This system ensures that Reclink has reliable, up-to-date information for decision-making, reporting, and understanding our impact in the community.